상관계수와 cross correlation
상관계수(correlation coefficient)는 통계학 쪽에서 사용되는 용어이고, cross correlation은 신호처리 분야의 용어이다. 그리고 NCC(normalized cross correlation)도 신호처리 분야 용어이다.
수식적으로 보면 상관계수 계산식과 NCC 계산식은 매우 유사하다 ($\bar{x}$: X의 평균, $\sigma_x$: X의 표준편차, $n$: 데이터 개수, $x_i$: i번째 관측 데이터의 X 속성 값, $f(x), g(x)$: x에서의 두 신호 값).
$$상관계수(X, Y) = \frac{1}{n} \sum_{i=1}^{n}{\frac{(x_i - \bar{x})(y_i - \bar{y})}{\sigma_x \sigma_y}}\tag{1}$$
$$NCC(f, g) = \frac{1}{n} \sum_{i=1}^{n}{\frac{f(x_i) g(x_i)}{\sigma_f \sigma_g}} \text{ or } \frac{1}{n} \sum_{i=1}^{n}{\frac{(f(x_i)-\bar{f})(g(x_i)-\bar{g})}{\sigma_f \sigma_g}} \tag{2}$$
그런데, 두 식이 사용되는 목적이나 응용은 조금 다르다. 상관계수(correlation coefficient)는 두 속성 or 변량의 상호 연관성을 -1 ~ +1 사이의 값으로 수치화한 것이다. 예를 들어, 키와 몸무게의 관계, 수업 참여도와 성적의 관계, 환율과 금리의 관계 등 두 변인의 연관관계를 분석하는 것이 목적이다. 반면에, cross correlation이나 normalized cross correlation은 두 신호(음성신호, 영상신호 등)의 형태적 유사성을 단지 수치적으로 계산한 것이다. 여기서 'cross'라는 용어는 이동, 교차의 의미로서 두 신호를 서로 겹쳐서 correlation을 계산하기에 붙여진 이름이다. 그리고 두 신호가 겹쳐지는 시점은 한 신호를 shift시킴으로써 다양하게 조정될 수 있다. cross correlation이 사용되는 대표적인 예로 템플릿 매칭을 생각할 수 있다. 식은 거의 같지만 적용에 있어서 어감이나 느낌은 상당히 다름을 알 수 있다.
이 글은 상관계수와 cross correlation에 대해 최근 깨달은 것들은 정리한 글이다. 또한, 공분산(covariance), 분산(variance), correlation과 covariance 차이, auto correlation 등 관련 용어들도 같이 정리한다.
사실 이 글을 쓰게 된 계기는 아내 때문이다. 아내가 요즘 '연구방법론'(객관적 연구를 위한 과학적 방법론)을 공부하면서 t-검정, 상관분석 등을 공부하고 있다. 그러면서 책을 봐도 무슨 말인지 모르겠다고 어려워한다. 그래서 이래 저래 설명해 주게 되었는데, 사실은 설명을 하면서 스스로 배우고 깨달은 것들이 더 많다. 막연하게만 알고 있던 covariance(공분산)의 의미를 다시 깨닫게 되었고 correlation과 covariance의 차이도 보다 확실히 알게 되었다. 그리고 상관계수나 공분산(covariance)에서 두 변량의 값이 서로 페어링(pairing)된 값이라는 점도 새로운 깨달음이다.
공분산(covariance)
데이터 분포의 평균, 분산, 표준편차는 통계에서 가장 기초적인 개념이다. 이들 중 분산(variance)은 측정된 데이터들이 평균을 중심으로 얼마나 모이고 흩어져 있는지를 나타내는 지표로서 "(편차)2의 평균"으로 계산된다 (편차 = 데이터값 - 평균). 그리고 분산에 제곱근을 취하면 표준편차가 된다.
$$Var(X) = \frac{1}{n} \sum_{i=1}^{n}{(x_i - \bar{x})^2}\tag{3}$$
$$Std(X) = \sqrt{Var(X)}\tag{4}$$
이 때, 한가지 주의해야 할 점은 평균, 분산, 표준편차는 데이터 분포에 대한 특성값이고, 편차는 데이터 각각에 대한 특성값이라는 점이다. 예를 들어, 전국 학생들의 키를 분석한다고 했을 때 측정된 학생들의 키의 평균은 얼마, 분산은 얼마라고 말할 수 있겠지만 데이터 각각(철수의 키, 영희의 키, ...)에 대해 평균, 분산, 표준편차가 얼마다고 말하는 것은 이치에 맞지 않는다.
분산이 데이터의 흩어진 정도를 나타내는 값이라면 공분산(covariance)는 어떤 의미일까? 일단, 분산이 하나의 변수(e.g. 키)에 대해 계산되는 반면에 공분산(covariance)은 두 변량(e.g. 키, 몸무게)에 대해 계산된다. 관측된 데이터가 n개일 때, 두 변수 X, Y 사이의 공분산 Cov(X, Y)는 아래와 같이 계산된다.
$$Cov(X, Y) = \frac{1}{n} \sum_{i=1}^{n}{(x_i - \bar{x})(y_i - \bar{y})}\tag{5}$$
식 (3)과 (5)를 자세히 살펴보자. X의 분산은 자신의 편차에 편차를 곱한 평균이다. 반면에 X와 Y의 공분산은 X의 편차에 Y의 편차를 곱한 평균이다. X의 편차에 Y의 편차를 곱한다는 말의 의미는 무엇일까? 편차는 +, - 부호를 가진 값이기 때문에 두 편차를 곱한 결과는 +일 수도 있고 -일 수도 있다. 분산(variance)는 항상 양수(0 이상)이지만 공분산(covariance) 값은 +일 수도 -일 수도 있음에 주의하자. X와 Y의 공분산은 데이터들의 X 편차와 Y 편차의 부호가 서로 같을수록 큰 +값을 갖고 부호가 서로 다를수록 -로 큰 값을 갖는다. 그리고 X의 자체 분산과 Y의 자체 분산이 클수록 X, Y의 공분산의 절대값도 증가한다.
공분산을 이해하기 위해서는 계산에 사용되는 두 변량의 값이 서로 페어링(pairing)된 값이라는 것을 인지하는 것이 중요하다. 식 (5)에서 보면 $x_i$에는 $y_i$가 곱해지지 $y_j$가 곱해지지 않는다. 이것이 앞서 중요하게 깨달았다고 했던 두 변량이 서로 페어링(pairing)된다는 것과 관련된다. 페어링 관점에서 보면 식 (5)에서 $x_i$는 i번째 데이터의 X 속성값, $y_i$는 동일한 데이터의 Y 속성값으로 이해할 수 있다. 예를 들어 모집단=전국학생, X=키, Y=몸무게로 생각해 보자. 그리고, 측정된 표본집단에서 키와 몸무게의 공분산을 구하는 문제를 생각해 보자. 이 때, 페어링 관점에서 철수의 키에 대해서는 철수의 몸무게와 비교하고 영희의 키는 영희의 몸무게를 비교해야지 철수의 키와 영희의 몸무게를 비교해서는 안된다. 그리고 이러한 페어링 관계는 공분산 뿐만 아니라 상관계수 계산에도 동일하게 적용된다.
※ 신호처리 분야에서는 2차원 평면에 점들이 있을 때 이 점들의 X좌표와 Y좌표의 공분산을 구하는 문제를 생각할 수 있다. 이 때, 각각의 점들을 데이터로 볼 수 있고 이 점들의 X좌표와 Y좌표는 서로 페어링된 값으로 볼 수 있다.
correlation과 covariance
두 변수의 correlation은 두 변량의 곱의 평균으로 정의된다.
$$Corr(X, Y) = \frac{1}{n} \sum_{i=1}^{n}{x_i y_i}\tag{6}$$
correlation이란 단어 뜻으로 보면 '상호연관'이 떠오른다. 그런데, 곱해서 합하면 왜 상호연관이 측정되는지는 언뜻 이해가 어렵다. 그런데, X의 값의 범위가 한정되어 있고 Y의 값도 범위가 한정되어 있는 경우를 생각해 보면, 곱의 합은 X의 분포와 Y의 분포가 서로 일치할수록 증가한다 (모든 i에 대해 xi = yi일 때 최대).
correlation은 두 데이터 분포의 유사도를 측정하는 도구로서 두 분포가 일치할 때 가장 높은 값을 갖는다. 그런데, 두 분포가 서로 위치적으로 떨어져 있는 경우에는 분포의 형태가 유사하더라도 낮은 correlation 값을 갖게 된다. 따라서, 두 분포의 형태 or 경향성의 유사도를 측정할 때에는 각 데이터 분포에서 평균을 뺀 후에 correlation을 계산하는 것이 효과적이다 (zero-normalized correlation).
$$\text{zero-normalized }Corr(X, Y) = \frac{1}{n} \sum_{i=1}^{n}{(x_i - \bar{x})(y_i - \bar{y})}\tag{7}$$
그런데, zero-normalized correlation 식을 보면 식 (5)의 covariance 식과 동일함을 알 수 있다. 즉, 바꾸어 말하면 covariance는 zero-normalized correlation으로 볼 수 있다.
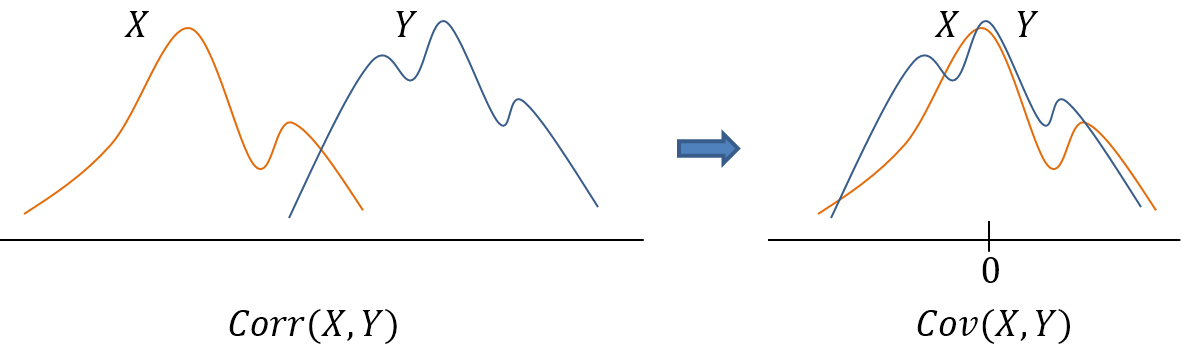
※ 분야에 따라서는 correlation과 covariance의 용어가 혼용되는 경우가 많다.
상관계수와 covariance
상관계수(correlation coefficient)는 통계학 분야에서 나오는 용어이다. 흔히, 통계라고 하면 수학 쪽으로만 생각하기 쉬운데 통계를 '사례를 모으고 분석해서 현상을 이해하는 연구 방법론'으로 본다면 통계는 경제학, 심리학, 사회과학, 의학 등 전 분야에 걸친 방법론이다.
상관계수(correlation coefficient)는 두 변량 X, Y 사이의 correlation 정도를 -1 ~ +1 사이의 값으로 수치화한 척도이다 ($\bar{x}$: X의 평균, $\sigma_x$: X의 표준편차, $n$: 데이터 개수, $x_i$: i번째 데이터의 X 속성 값, $y_i$: i번째 데이터의 Y 속성 값)
$$상관계수(X, Y) = \gamma = \frac{1}{n} \sum_{i=1}^{n}{\frac{(x_i - \bar{x})(y_i - \bar{y})}{\sigma_x \sigma_y}}\tag{8}$$
그런데 상관계수 식을 잘 보면 식 (7)의 공분산 식과 연관이 큼을 알 수 있다. 앞서, 공분산은 zero-normalized correlation으로 볼 수 있다고 했다. 그런데, zero-normalization을 했더라도 두 분포가 가지고 있는 값의 크기의 스케일(scale)에 따라서 correlation 값이 달라질 수 있다. 따라서 순수하게 상관도만 분석하기 위해서는 각 분포의 스케일을 1로 정규화한 후에 correlation을 계산할 필요가 있으며 이렇게 정규화된 두 분포의 상관도를 계산한 것이 상관계수(correlation coefficient)이다. 여기서 scale이란 값의 단위 또는 크기의 범위를 말한다. 예를 들어, 한국 중학생들의 키와 몸무게의 상관도를 분석하기 위해 키는 미터(meter) 단위로 몸무게는 킬로그램(kg) 단위로 측정했다고 하자. 그러면 평균을 보상한 키는 -0.3 ~ 0.3 m 사이의 값을, 몸무게는 -20 ~ 20 kg 사이의 값을 가질 것이다. 이렇게 값의 단위가 서로 다른 두 변량을 그대로 correlation을 취하면 그 결과는 예측이 힘들며 분석도 어렵게 된다. 하지만, 각 변량을 표준편차로 나누어 정규화한 후에 correlation을 계산하면 그 결과는 항상 -1 ~ +1 사이의 값을 갖게 된다 (Why? Cauchy-Schwarz inequality).
정리하면 상관계수(correlation coefficient)는 평균과 스케일을 보상한(평균은 0으로, 표준편차는 1이 되도록 정규화한) 후 계산한 두 변량의 correlation이다.
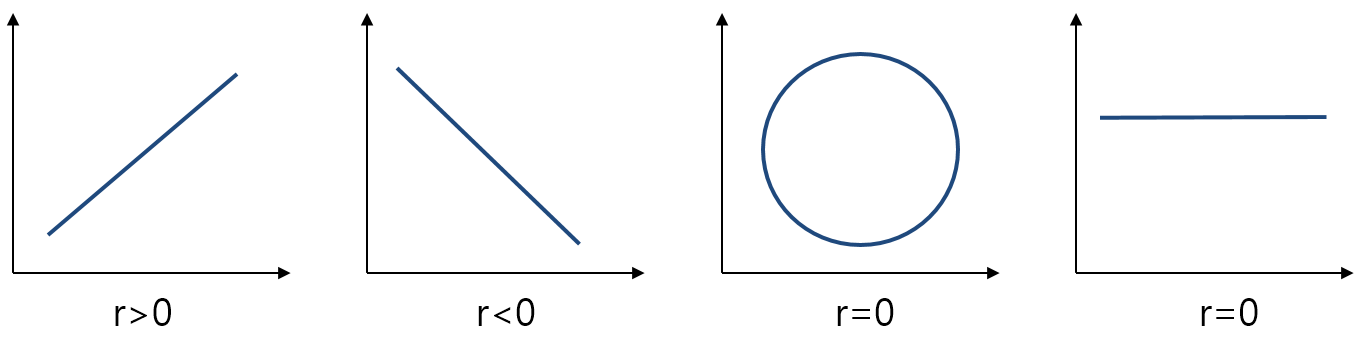
상관계수 계산값 r은 항상 -1 ~ +1 사이의 값을 가지는데, r>0이면 양의 상관관계(X가 클수록 Y도 증가), r<0이면 음의 상관관계(X가 클수록 Y는 작은 값), r = 0이면 X, Y가 서로 아무 관계가 없다는 것을 의미한다. 그리고 상관계수를 계산할 때 두 변량이 항상 페어링(pairing)된다는 점도 잊어서는 안된다.
※ 상관계수의 해석: (댓글을 읽다보니 상관계수의 의미에 대해 오해가 있을 수 있겠다 싶어서 내용을 덧붙입니다) 상관계수가 높다는 것은 두 대상의 경향성이 유사하다는 것이지 값이 같다는 의미는 아니다. 예를 들어, 예측값과 관측값의 상관계수를 계산한다고 했을 때, 예측된 값이 40, 50, 60일 때 실제 관측된 값이 90, 100, 110이라고 해 보자. 이 경우 예측값과 실제값은 상당한 오차가 있다. 하지만 상관계수를 계산해 보면 매우 높은 값을 갖는다. 상관계수는 평균과 스케일(표준편차)을 정규화한 후에 계산하기 때문이다. 따라서, 응용에 따라 경향성 뿐만 아니라 값 자체도 유사해야 한다면 식 (6)처럼 평균, 표준편차 차이를 제거하지 말고 원본 값에 대해 correlation을 계산해야 한다.
cross correlation과 correlation
이제 신호처리 분야로 돌아와 보자. 사회과학, 심리상담학, 경제학 등에서의 correlation 분석은 두 변인 사이의 상호 연관도를 분석하기 위한 것으로서 그 데이터 값들이 서로 페어링(pairing)된 것이 특징이다. 반면에, 신호처리 분야에서는 단지 두 신호가 얼마나 형태적으로 유사한지를 수치적으로 계산한 것이다. 그리고 두 신호를 서로 겹쳐서 계산하기 때문에 cross correlation이라 부르며 두 신호를 어떻게 겹치는지(displacement)에 따라서 pairing 관계가 달라진다.
연속된 두 신호 f(t), g(t)가 있을 때 cross correlation은 일반적으로 다음과 같이 정의된다 ($\tau$는 displacement 파라미터).
$$f \star g(\tau) = \int_{-\infty }^{\infty } f(t) g(t+\tau) dt \tag{9}$$
그리고 이를 이미지 프로세싱에 적용하면 영상신호 f(x,y)와 템플릿 t(x,y)에 대해 cross correlation을 아래와 같이 계산할 수 있다.
$$\frac{1}{n} \sum_{x,y} f(x,y)t(x,y) \tag{10}$$
만일 영상 밝기 차이를 보상한 후에 correlation을 구하고 싶다면 아래와 같이 계산할 수 있다 (zero-normalized cross correlation).
$$\frac{1}{n} \sum_{x,y} (f(x,y) - \bar{f})(t(x,y) - \bar{t}) \tag{11}$$
또는 아래와 같이 각각의 신호를 표준편차로 나누어 스케일 차이를 보상한 normalized cross correlation을 구할 수도 있다.
$$NCC = \frac{1}{n} \sum_{x, y} \frac{f(x, y)t(x, y)}{\sigma_f \sigma_t} \tag{12}$$
그리고 평균과 스케일을 모두 보상한 normalized cross covariance를 구할 수도 있다 (계산 결과는 -1 ~ +1 사이의 값을 갖는다).
$$\frac{1}{n} \sum_{x, y} \frac{(f(x, y) - \bar{f})(t(x, y) - \bar{t})}{\sigma_f \sigma_t} \tag{13}$$
한 가지 하고 싶은 말은 용어나 수식에 너무 집착하지 말자는 것이다. 정말 중요한 것은 그 '의미'이다. NCC 식은 식 (12)가 맞겠지만 식 (13)을 NCC로 사용해도 큰 문제는 없다. 의미만 알면 자신이 원하는 목적에 맞게 식을 골라 쓰거나 변형해서 사용할 수 있다.
마지막으로 신호처리 분야에 auto correlation이라는 게 있다. auto correlation은 서로 다른 두 신호가 아니라 자신과 자신을 correlation하는 것을 의미한다.
$$f \star f(\tau) = \int_{-\infty }^{\infty } f(t) f(t+\tau) dt \tag{14}$$
by 다크 프로그래머