최적화 기법의 직관적 이해
일전에 최적화 기법에 대해 정리하는 글(기계학습 - 함수 최적화 기법 정리)을 썼었는데, 지금에 와서 보니 너무 수식만 가득한 글이었던 것 같습니다. 그래서 수식보다는 좀더 직관적으로 이해할 수 있으면 좋겠다 싶어서 다시 글을 적어 봅니다.
최적화 문제하면 언뜻 수학 문제로만 보이지만 영상처리를 비롯하여 다양한 분야에서 조금만 이론적으로 깊게 들어가도 최적화 문제로 귀결되는 경우가 많습니다. 한번쯤 알아두면 어딘가에는 도움이 되리라 생각합니다 ^^
1. 최적화 문제
먼저, 최적화(optimization) 문제란 어떤 목적함수(objective function)의 함수값을 최적화(최대화 또는 최소화)시키는 파라미터(변수) 조합을 찾는 문제를 말합니다.
예를 들어 카메라 캘리브레이션에서 카메라의 파라미터(초점거리 등)를 찾는 문제, 서로 다른 시점에서 찍은 두 카메라 영상에서 3D 정보를 복원하는 문제, 비디오 영상에서 비디오를 촬영할 당시의 카메라의 궤적을 복원하는 문제, 사람에 대한 비디오 영상에서 사람의 관절의 움직임을 스켈레톤(skeleton)으로 모델링하는 문제, 고저가 있는 지형에서 목적지까지의 차량의 에너지(연료) 소모를 최소화하는 이동 경로를 찾는 문제 등이 모두 최적화 문제에 해당됩니다.
이 때, 만일 목적함수가 f(x) = 2x + 1 등과 같이 하나의 파라미터(변수)로 되어 있다면 일변수 함수에 대한 최적화 문제가 되며 f(x,y) = xy - x + 5 등과 같이 여러 개의 파라미터(변수)로 되어 있다면 다변수 함수에 대한 최적화 문제가 됩니다.
또한 목적함수가 f(x1,x2,...,xm) = b + a1x1 + a2x2 + ... + amxm 과 같이 모든 파라미터(변수)에 대해 일차 이하의 다항식으로 구성되면 선형 최적화(linear optimization) 문제라 하고 f(x,y) = ysinx + x, f(x,y) = x2 + y, f(x,y) = xy - 1 등과 같이 그 외의 경우를 비선형 최적화(nonlinear optimization) 문제라 부릅니다.
그리고 목적함수 외에 파라미터가 만족해야 할 별도의 제약조건이 있는 경우를 constrained optimization 문제, 별도의 제약조건이 없는 경우를 unconstrained optimization 문제라 부릅니다.
어찌 되었든 최적화(optimization) 문제란 우리가 원하는 어떤 조건(함수값을 최소화 또는 최대화)을 만족시키는 최적의 파라미터(변수) 값을 찾는 문제를 말하며 여기서 다루고자 하는 최적화 문제는 별도의 제약조건이 없는 일반적인 비선형 최적화(unconstrained nonlinear optimization) 문제입니다.
최적화(optimization) 문제는 크게 최대화(maximization) 문제와 최소화(minimization) 문제로 나눌 수 있는데, 목적함수가 이윤, 점수(score) 등인 경우에는 최대화 문제, 비용(cost), 손실(loss), 에러(error) 등인 경우에는 최소화 문제로 볼 수 있습니다. 그런데, f를 최대화시키는 것은 -f를 최소화시키는 것과 동일하므로 방법론 상으로는 최대화 문제와 최소화 문제를 모두 동일하게 볼 수 있습니다. 따라서 이 글에서는 편의상 최적화 문제를 최소화(minimization) 문제로 한정하겠습니다.
2. 최적화 원리
최적화 문제를 푸는 가장 기본적인 원리는 비교적 단순합니다. 그건, 현재 위치에서 함수값이 감소(최대화 문제라면 증가)하는 방향으로 조금씩 조금씩 파라미터 값을 이동해 나가는 것입니다. 즉, 한걸음을 내딛은 후 그 위치에서 어느 방향이 가장 내리막 길인지를 봐서 그 방향으로 한 걸음을 내딛고, 또 다시 그 위치에서 가장 내리막 방향을 찾고... 하는 과정을 더 이상 내려갈 수 없는 곳(local minima)에 다다를 때까지 반복합니다. 그리고 이런 과정을 반복하다 보면 언젠가는 (비록 local minimum일수도 있겠지만) 함수값이 최소화되는 지점을 발견할 수 있을 것이라는 원리입니다.

<그림 1> 그림출처: http://blog.datumbox.com/
이 때, 가장 중요한 이슈는 어느 방향으로 내려갈 것인지와 한번에 얼마큼씩 이동할 것인지를 결정하는 것입니다. 그리고 기존의 여러 최적화 기법들(뉴턴 방법, gradient descent 방법, Levenberg-Marquardt 방법 등)이 있지만 이들의 차이는 결국 이동할 방향과 이동할 양을 어떤 방식으로 결정하느냐의 차이일 뿐입니다.
그리고, 이동할 방향과 이동할 양을 결정할 때 사용되는 가장 기본적인 수학적 원리는 일차미분(기울기)과 이차미분(곡률)의 개념입니다.
3. 일차미분을 이용한 최적화
일차미분(f')을 이용한 함수 최적화 기법의 가장 단순한 형태는 다음 수식에 따라 임의의 시작점 x0부터 시작하여 수렴할 때까지 x를 변화시키는 것입니다.

여기서 λ는 한번에 얼마나 이동할지를 조절하는 step size 파라미터로서 일단은 고정된 상수(λ>0)로 가정합니다.
즉, 일차미분을 이용한 함수 최적화는 현재 지점에서 일차미분(기울기)이 양수(f'>0)이면 x를 감소시키고, 음수(f'<0)면 x를 증가시키는 방식으로 f가 극소(minima)가 되는 지점을 찾는 것입니다.

<그림 2> 일차미분을 이용한 최적화 원리
간단한 예로, f(x) = x4을 최소화시키는 x를 x0 = 2부터 시작하여 구해보겠습니다. 스텝(step) 파라미터는 λ = 0.01로 설정하고 식 (1)의 탐색과정을 200회 반복한 결과는 아래와 같습니다.

<그림 3> 일차미분을 이용한 최적화 예
위 그림에서 볼 수 있듯이 일차미분 방법을 이용하면 f가 최소화되는 방향으로 x가 정상 이동함을 확인할 수 있습니다.
그런데, 한가지 문제는 극소점 근처에서는 수렴 속도가 급격히 떨어져서 200회나 진행했음에도 불구하고 실제 극소점(x = 0) 근처에 다다르지 못했다는 점입니다. 그 이유는 극소점에 다가갈수록 f'이 0에 가까워져서 식 (1)에서 스텝의 크기도 함께 줄어들기 때문입니다.
수렴속도의 문제를 해결하기 위하여 손쉽게 생각할 수 있는 방법은 스텝(step) 파라미터 λ의 값을 증가시키는 것입니다. 아래 그림은 스텝 파라미터를 λ = 0.03 (3배 증가)로 했을 때와 λ = 0.13 (13배 증가)로 했을 때의 결과입니다.
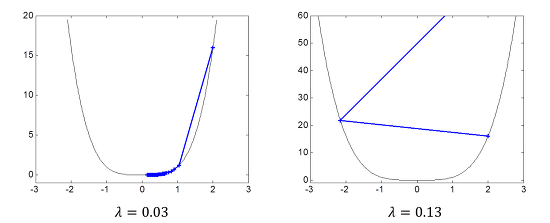
<그림 4>
여기서 우리는 흥미로운 점 2가지를 알 수 있습니다. 스텝 파라미터를 키우면 수렴 속도가 증가하긴 하나 극소점 근처에서는 그 차이가 크지 않다는 점(λ = 0.03 예), 그렇다고 스텝 파라미터를 너무 키우면 아예 발산해 버릴 수도 있다는 점(λ = 0.13 예)입니다.
앞서 최적화 기법의 핵심은 이동할 방향과 이동할 크기를 어떻게 정하느냐의 문제라고 했습니다. 지금까지 설명한 일차미분을 이용한 최적화 기법의 가장 큰 장점은 이동하고자 하는 방향이 항상 올바른 방향을 향한다는 점입니다. 하지만 step size에 대해서는 어떠한 해결책도 제시해 주지 못합니다. Step size가 너무 작으면 수렴 속도가 느리고 또 너무 크면 수렴을 하지 못하고 발산해 버릴 수도 있습니다. 그리고 적절한 step size의 크기는 함수마다 모두 달라질 수 있습니다.
☞ 지금까지 설명한 일차미분을 이용한 최적화 기법을 Gradient Descent 방법이라 부르며 그 특성 및 장단점 또한 동일합니다.
4. 이차미분을 이용한 최적화
앞서 설명한 일차미분을 이용한 최적화 기법의 문제점을 해결하기 위한 한 방법은 일차미분(f')과 함께 이차미분(f'')을 이용하는 것입니다.

앞서 f(x) = x4 예에 식 (2)를 적용하면 20번의 반복(iteration)만에 다음과 같은 수렴 결과를 보여줍니다 (x0 = 2).

<그림 5> 이차미분을 이용한 최적화 예
그림 3과 그림 5의 결과를 확인하면 그 차이는 확연합니다. 일차미분을 이용한 경우(그림 3)에는 200회나 탐색을 진행했음에도 극소점에 다다르지 못한 반면 이차미분을 함께 이용한 경우(그림 5)에는 단 20 스텝만에 극소점에 거의 수렴함을 확인할 수 있습니다. 또한 식 (2)는 스텝 파라미터 λ를 요구하지 않는다는 특징도 있습니다 (f''을 이용하여 스텝의 크기를 스스로 결정).
☞ 우리가 알고 있는 뉴턴법(Newton's method), 가우스-뉴턴법(Gauss-Newton method), LM(Levenberg-Marquardt) 방법 등이 모두 이차 미분을 이용한 최적화 기법에 해당합니다.
얼핏 보면 모든 면에서 이차미분을 이용하는 것을 훨씬 효과적인 것처럼 보입니다. 하지만 이차미분을 이용한 방법은 크게 2가지 문제점을 갖고 있습니다. 그 한가지는 변곡점(f''=0) 근처에서 매우 불안정한 이동 특성을 보인다는 점입니다. 예를 들어, f(x) = x3 - 2x + 1라 하고 x0 = 0인 경우 f''(0) = 0이기 때문에 식(2)가 아예 정의가 안되는 문제점이 발생합니다 (그림 6a). 또한 정확히 변곡점이 아니라 하더라도 변곡점 근처에서는 f'' = 0에 가까운 값을 갖기 때문에 스텝(step)의 크기가 너무 커져서 아에 엉뚱한 곳으로 발산해 버릴 수도 있습니다 (그림 6b). 하지만 일차미분을 이용한 방법의 경우에는 나누기가 없기 때문에 이러한 문제가 발생하지 않으며 변곡점에서 출발한 경우에도 정상적으로 해를 찾을 수 있습니다 (그림 6c).

<그림 6> 이차미분을 이용한 최적화 기법의 문제점 I
이차미분을 이용한 최적화 기법의 2번째 문제점은 이동할 방향을 결정할 때 극대, 극소를 구분하지 않는다는 점입니다. 앞서 f(x) = x3 - 2x + 1의 예에서 x0 = -0.5라 하면 이차미분을 이용한 방법은 극소점이 아닌 극대점을 향해 수렴(그림 7a)해 버리는 반면 일차미분을 이용한 경우에는 정상적으로 극소점을 향해 수렴함(그림 7b)을 확인할 수 있습니다.

<그림 7> 이차미분을 이용한 최적화 기법의 문제점 II
정리해 보면 일차미분을 이용한 방법은 항상 옳은 방향을 향하지만 스텝(step)의 크기를 정하는데 어려움이 있고 이차미분을 이용한 방법은 보다 빠르게 해를 찾을 수 있지만 변곡점(f''=0) 근처에서 문제의 소지가 있으며 극대, 극소를 구분하지 못한다는 문제점이 있습니다. 그리고 그동안 연구되어온 다양한 최적화 기법들은 결국 이러한 단점을 극복하기 위한 여러 노력의 결과로 볼 수 있습니다. 구체적인 극복 방법들을 살펴보기 전에 먼저 이차미분을 이용한 최적화 기법의 기본 원리에 대해 살펴보겠습니다.
이차미분을 이용한 최적화 기법의 기본 원리는 현재 지점에서 구한 f'' 값을 다른 모든 구간으로 확대 적용하는데 있습니다. 앞서, f(x) = x4의 예에서 f''(2) = 48입니다. 그런데, x = 2뿐만 아니라 다른 모든 x에서도 f''(x) = 48라고 가정하면 이러한 f는 f(x) = 24x2 + bx + c 꼴의 이차함수(포물선)가 됩니다. 그리고 f(2)와 f'(2)도 현재 지점과 같게 일치를 시키면 f(x) = 24x2 - 64x + 48가 됩니다. 이와 같이 현재 지점에서의 함수의 변화를 이차 포물선으로 근사시킨 후 원래의 함수가 이 근사 포물선과 같을 것이라고 가정해 버립니다. 그러면 함수의 값을 최소화시키는 지점은 포물선의 극점일 것이므로 구해진 포물선의 극점으로 x를 이동시키는 것이 식 (2)의 원리입니다 (그림 8).

<그림 8> 이차미분을 이용한 최적화 원리
☞ 사실 이차미분을 이용한 최적화는 테일러 급수(Taylor series)와 밀접한 관련이 있습니다. 임의의 함수 f(x)에 대한 x = xk에서의 이차 테일러 근사는 f(x) = f(xk) + f'(xk)*(x-xk) + f''(xk)/2*(x-xk)2 로 주어집니다. 그리고 이 이차 다항식의 극점(f'=0인 지점)을 구해보면 x = xk - f'(xk)/f''(xk)가 나옵니다. 따라서 식 (2)는 함수를 2차 테일러 다항식으로 근사한 후 x를 근사 다항식(포물선)의 극점으로 이동시키는 수식입니다.
5. Line Search 방법
Line search 방법은 최적화 기법에서 스텝(step)의 크기를 결정하는 방법에 관한 것으로서 앞서 설명한 최적화 기법들의 문제점을 효과적으로 극복할 수 있는 해법 중 하나입니다.
예를 들어 어떤 사람이 깜깜한 밤에 후레쉬 하나만 들고 산을 내려오고 있습니다. 그런데 그 사람은 바로 발밑의 지형만을 보고 어디로 내려갈지 그리고 얼마나 내려갈지를 정합니다. 그리고는 눈을 질끈 감고 점프를 합니다. 운이 좋으면 산을 많이 내려올 수 있지만 운이 나쁘면 건너편 언덕 위로 올라가 버릴 수도 있습니다. 여기까지가 기본적인 최적화 기법의 접근 방식입니다. 그런데, 좀더 현명한 사람이라면 뛰고자 하는 방향(라인)을 따라서 미리 후레쉬를 비춰보고 실제 지형을 살펴본 후에 얼마나 점프하면 좋을지를 결정할 것입니다.
앞서 일차미분을 이용한 최적화 기법은 항상 옳은 방향을 향하지만 스텝(step)의 크기를 정하는 것이 문제라고 했습니다. 즉, 스텝의 크기가 너무 크면 발산의 위험이 있고 또한 극점 근처에서는 수렴 속도가 느려지는 문제점이 있었습니다. 또한 이차미분을 이용한 경우에도 변곡점(f'') 근처에서는 탐색이 불안정해지는 문제점이 있었습니다. 그런데, 사실 이러한 문제의 원인은 스텝의 크기를 현재 지점에서의 국소적인 변화(f' 또는 f'')만을 보고 정하는데 있습니다. Line search 방법은 이동하고자 하는 방향을 따라서 실제 함수값(f)의 변화를 미리 살펴본 후에 (함수값을 최소화하도록) 이동할 양을 결정하는 방식입니다.
Line search 방법에도 여러 가지가 있는데 직관적으로 이해할 수 있는 방법으로는 backtracking line search 방법과 golden section search 방법이 있습니다. Backtracking line search 방법은 일단 이동하고자 하는 방향을 따라서 최대한 멀리 가봅니다. 그리고 해당 지점의 함수값이 현재의 함수값에 비해서 충분히 작아졌는지 검사합니다. 만일 충분히 작지 않다면 점차적으로(보통 1/2씩) 거리를 줄여가면서 다시 함수값을 비교합니다. 그래서 충분히 작아졌다고 판단이 되면 해당 지점으로 점프를 합니다. 그리고 점프한 지점에서 다시 이동할 방향을 잡고 line search 알고리즘을 적용하는 방식입니다 (그림 9a). Golden section search(황금분할탐색) 방법은 탐색구간의 내부를 황금비율인 1:1.618로 분할해 가면서 구간 내에서 함수값이 최소가 되는 지점을 탐색한 후 해당 지점으로 점프하는 방식입니다 (그림 9b).

<그림 9> line search 방법
☞ Backtracking line search 방법에서 충분히 작아졌는지 여부는 현재 지점에서의 함수값을 f(xk), 이동하고자 하는 지점에서의 함수값을 f(xk + △x)라 할 때 f(xk + △x) - f(xk) ≤ △x*cf'(xk)를 만족하는지 여부로 결정하며(c는 0과 1 사이의 상수) 이 조건식을 Armijo–Goldstein 조건이라고 합니다.
☞ 일차미분을 이용한 최적화 기법은 항상 옳은 방향을 향하기에 line search 방법을 일차미분 최적화 방법과 결합하면(이동할 방향은 일차미분으로, 이동할 크기는 line search로 결정) 앞서 여러가지 문제점들을 극복할 수 있는 좋은 함수 최적화 방법이 됩니다.
6. Trust Region 방법
앞서 line search 방법이 주로 일차미분을 이용한 최적화 기법의 단점을 극복하기 위한 방법이라면 trust region(신뢰 영역) 방법은 이차미분을 이용한 최적화 기법의 단점을 극복하기 위한 방법입니다.
☞ 사실 trust region 방법은 복잡한 함수의 변화를 좀더 단순한 함수로 근사(approximation)할 경우에 근사 정확도를 보장하기 위해서 사용되는 일반적인 방법이지만 여기서는 이차함수로 근사하는 경우로 한정하여 설명하겠습니다.
앞서 설명했듯이 이차미분을 이용한 최적화 기법의 핵심 원리는 모든 구간에서 함수의 이차미분(f'') 값이 상수라고 가정하고 함수의 변화를 이차함수(quadratic function)로 근사한 후 근사 함수의 극점으로 이동하는데 있습니다. 그런데, 이 가정의 가장 큰 문제점은 실제 함수는 이차함수가 아니라는데 있습니다.
Trust region 방법은 근사 함수에 대한 신뢰 영역(trust region)을 정의한 후 이동할 목적지에 대한 탐색 범위를 이 영역 내부로만 제한하는 방법을 말합니다.

<그림 10> trust region 방법
실제 구현 측면에서, 최소화시키고자 하는 함수를 f(x), 현재 위치를 x = xk, 현재의 trust region을 |x - xk| ≤ rk라 하면 먼저 식 (2) 등을 이용하여 다음으로 이동할 지점을 추정합니다. 만일 이동할 지점이 trust region을 벗어날 경우에는 스텝의 크기를 줄여서 trust region를 벗어나지 않도록 (trust region의 경계와 만나는 지점으로) 위치를 수정합니다. 이와 같이 결정된 지점으로 이동한 후 다시 trust region 방식의 탐색을 반복하는 구조입니다. 이 때, trust region의 크기는 매 반복마다 조정될 수 있으며 근사 2차함수가 현재의 trust region 내에서 원래 함수를 얼마나 잘 근사하는지에 따라서 조정됩니다. 통상적으로 근사오차가 허용치 이하일 경우에는 trust region의 크기를 키우고 허용치 이상일 때에는 trust region의 크기를 줄이는 방법이 사용됩니다.
☞ Trust region의 크기를 조절할 때, 현재의 trust region 내의 모든 지점에서 근사 오차를 확인하는 것은 비효율적입니다. 따라서, 다음으로 이동할 지점에 대해서만 근사오차를 계산하여 trust region의 크기를 조정합니다. 그리고 필요하다면 trust region의 크기 조정에 따라 이동 지점도 같이 수정합니다.
☞ 비선형 최소자승(nonlinear least squares) 문제에 대한 최적화 기법으로 잘 알려진 Levenberg-Marquardt 방법도 기본적으로는 trust region 방법에 속합니다.
7. Damping & Saddle-free 방법
마지막으로 damping 방법은 앞서의 line search 방법, trust region 방법처럼 수렴의 안정성을 보장해주기 위한 방법입니다 (공식적인 용어는 아닙니다). 원래 damping 방법은 비선형 최소자승 문제(nonlinear least squares problem)에서의 대표적인 최적화 기법인 Levenberg-Marquardt 방법에서 사용된 기법을 일컫는 말입니다. 하지만 그 핵심 원리는 최소자승 문제뿐만 아니라 일반적인 최적화 문제에도 동일하게 적용될 수 있다고 생각합니다.
식 (2)의 이차미분을 이용한 최적화 방법에 damping 기법을 적용하면 아래와 같이 식을 보완할 수 있습니다.

이 때, 식 (3)에서 상수 μk(μk>0)가 damping factor이며 영어로는 '제동하는', '진폭을 억제하는' 이라는 의미를 갖습니다. 즉, damping 방법은 변곡점(f''=0) 근처에서 발산하려고 하는 원래의 시스템에 제동(억제)을 가함으로써 모든 경우에 부드럽게 동작하도록 만든 것입니다.
식 (3)에서 μk가 큰 경우에는 상대적으로 f''의 영향이 작아지기 때문에 일차미분을 이용한 최적화 기법과 유사해지고, 반대로 μk가 작은 경우에는 이차미분을 이용한 최적화 기법과 유사한 특성을 가집니다.
식 (3)에서 또 하나 눈여겨 볼 점은 f''에 절대값이 붙은 점입니다. 원래 식 (2)로 주어지는 이차미분을 이용한 최적화 기법의 문제점 중의 하나는 극대, 극소를 구분하지 못한다는 점입니다. 하지만 식 (3)과 같이 f''에 절대값을 씌우면 일차미분(f')의 부호에 의해서만 탐색 방향이 결정되기 때문에 항상 함수값을 최소화시키는 방향으로만 탐색을 진행하게 됩니다.
서두에 언급했지만 식 (3)은 잘 알려져 있거나 또는 일반 문헌 등에 소개되어 있는 식은 아닙니다. 하지만 식 (3)을 사용하면 수렴 속도가 빠르다는 이차 미분의 장점을 유지하면서도 변곡점 근처에서의 불안정성과 극대, 극소를 구분하지 못하는 두 가지 문제를 모두 해결할 수 있습니다.
☞ Damping 방법은 일종의 trust region 방법으로 볼 수 있는데, 그 이유는 μk가 일종의 trust region의 크기를 결정하는 역할을 하기 때문입니다(μk가 클수록 trust region의 크기가 작아지고 μk가 작을수록 trust region의 크기가 커짐). 앞서 trust region 방법에서와 마찬가지로 μk의 값은 매 최적화 스텝(step)마다 조절할 수 있습니다. 가장 간단한 방법은 이동할 지점의 함수값이 현재의 함수값에 비해 충분히 작은지를 검사하여 만일 그렇지 않은 경우에는 μk를 증가시키고(예를 들어 2배씩) 충분히 작은 경우에는 다시 μk를 감소시키는(예를 들어 1/3씩, 또는 기본값으로 되돌리는) 방법입니다.
☞ 서두에서 '생각합니다'라는 표현을 사용한 이유는 식 (3)의 방법이 기존에 나와 있는 일반적인 방법이 아니기 때문입니다(물론 이미 발표되어 있는데 제가 아직 모르고 있을 수도 있습니다). 식 (3)은 Levenberg-Marquardt 방법에서 사용된 damping 기법이 일반적인 최적화 기법에도 적용될 것 같아서 식을 세워 본 것입니다. 그리고 참고로 f''에 절대값을 씌우는 것은 작년(2014년) Y. Dauphin, R. Pascanu, C. Gulcehre, K. Cho, S. Ganguli, Y. Bengio. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization 논문에 발표된 아이디어로서 논문에서는 Saddle-free 방법이라는 명칭을 사용하였습니다.
8. 다변수 함수에서의 최적화
지금까지 설명한 최적화 원리 및 기법들은 모두 일변수 함수를 예로 들었지만 다변수 함수의 경우에도 그대로 확장 적용될 수 있으며 그 특성 및 장단점도 모두 동일합니다.
앞서 최적화 기법들을 다변수 함수로 확장 적용하기 위해서는 미분을 어떻게 구하느냐가 관건인데, 다변수 함수에서의 일차 미분은 그레디언트(gradient), 이차 미분은 헤시안(Hessian)이 됩니다. 그리고 그레디언트와 헤시안의 계산을 위해서는 편미분(partial differentiation)이 필요합니다.
먼저, 다변수 함수란 f(x1, x2, x3) = x12 + x2x3 등과 같이 두개 이상의 변수에 의하여 함수값이 결정되는 함수를 말합니다. 이 때, 함수 f(x1, x2, x3)가 점 p(p1, p2, p3)에서 어떤 변화 특성을 갖는지 분석할 때, x1만 변수로 놓고 나머지는 상수로 놓은 함수 f(x1, p2, p3)를 생각해 보면 x1 값이 변할 때 f의 값이 어떤 변화를 갖는지 분석할 수 있을 것입니다. 마찬가지 방식으로 x2, x3에 대해서도 각각의 방향으로의 함수값 변화 특성을 분석할 수 있습니다. 이와 같이 어느 한 변수의 방향축에 대해서만 변화율을 구한 것을 편미분(partial derivative)이라 부르고 f의 x에 대한 편미분을 ∂f/∂x로 표기합니다(위 예에서 ∂f/∂x1 = 2x1, ∂f/∂x2 = x3, ∂f/∂x3 = x2). 그리고 다변수 함수 f(x1, x2, ..., xn)에 대한 일차 미분은 다음과 같이 각 변수에 대한 일차 편미분으로 정의되며 이를 그레디언트(gradient)라 부릅니다.

또한 다변수 함수의 이차 미분은 아래와 같은 헤시안(Hessian) 행렬로 정의됩니다.

☞ 참고로, 자코비언(Jacobian)은 다변수 벡터 함수에 대한 일차 미분입니다. 다변수 벡터 함수란 F(x1, ..., xn) = (f1(x1, ..., xn), ..., fm(x1, ..., xn))과 같이 함수값이 벡터 형태로 나오는 함수를 말합니다. 이에 반해 함수값이 하나의 실수값(real value)으로 나오는 일반적인 다변수 함수는 다변수 스칼라(scalar) 함수라고 부릅니다. 그리고 다변수 벡터 함수에 대한 이차 미분은 따로 정의되지 않습니다.
이제 식 (1)의 일차 미분을 이용한 최적화 기법을 다변수 함수로 확장하면 잘 알려진 gradient descent 방법의 식이 됩니다 (단, x = (x1, x2, ..., xn)).

그리고 식 (2)의 2차 미분을 이용한 최적화 기법을 다변수 함수로 확장하면 일반적인 Newton 방법 식이 됩니다.

또한 식 (3)의 damping 방법을 다변수 함수로 확장하면 아래와 같이 식을 세울 수 있습니다.

단, |H|는 H를 고유값 분해한 후 고유값의 부호를 모두 +로 변경하여 얻은 행렬, I는 항등행렬을 나타냅니다.
☞ 앞서 설명한 바와 같이 식 (3)의 damping 방법은 일반적인 방법이 아니기 때문에 식 (8) 또한 기존의 알려진 방법이 아님을 참고하시기 바랍니다.
9. 비선형 최소자승 문제(nonlinear least squares problem)
마지막으로 비선형 최소자승 문제에 대한 최적화 기법에 대해 간략히 살펴보고 글을 마무리하고자 합니다. 지금까지 설명한 최적화 기법들은 임의의 함수에 적용 가능한 일반적인 최적화 방법들이었습니다. 하지만 목적함수(objective function)가 모델과 데이터 사이의 에러(error) 제곱합 형태로 주어지는 f(x) = Σei(x)2 형태의 최소자승(least squares) 문제에 대해서는 별도의 특화된 최적화 기법들을 존재합니다. 그리고 이러한 방법에는 가우스-뉴턴법(Gauss-Newton method), Levenberg-Marquardt 방법 등이 있습니다. 가우스-뉴턴법은 식 (7)과 유사한 형태이고 Levenberg-Marquardt 방법은 식 (8)과 유사한 형태입니다. 특성 및 장단점도 거의 동일합니다. 하지만 이들은 최소자승 문제의 최적화에만 적용할 수 있고, 일반적인 최적화 문제에는 적용할 수 없는 방법임에 유의하기 바랍니다. 하지만 우리가 풀고자 하는 대부분의 최적화 문제들이 최소자승 문제에 해당하기 때문에 이들에 대해서도 잘 알아둘 필요가 있습니다. 최소자승 문제에 대한 보다 자세한 내용에 대해서는 [기계학습] - 함수최적화 기법 정리 (Levenberg–Marquardt 방법 등) 글을 참고하시기 바랍니다.
10. Quasi-Newton 방법 (2015.6.20 추가된 내용)
앞서 설명한 최적화 기법들 중 일차미분의 gradient descent 방법은 수렴속도 면에서 효율성이 많이 떨어지기 때문에 실제 문제에서는 가급적 이차미분을 이용한 Newton 방법(trust region 또는 line search와 결합된)을 사용하는 것이 좋습니다. 그런데, Newton 방법을 적용하기 위해서는 Hessian 행렬을 계산하는 것이 가장 큰 문제입니다. Hessian 행렬을 계산하기 위해서는 목적함수에 대한 이차 도함수를 일일히 계산해야 하는데, 목적함수가 조금만 복잡해져도 이차 편미분을 종이 위에 직접 손으로 푸는 것을 거의 불가능하다고 볼 수 있습니다. 이러한 어려움으로 인해 이차 도함수를 직접 계산하는 대신에 근처의 함수값을 이용하여 근사적으로 계산하는 방법들이 실질적으로는 많이 사용되고 있습니다. 예를 들어, f(x) = x2의 x = 2에서의 일차미분값은 정확히 계산하면 f'(2) = 2*2 = 4이지만, 이를 근사적으로 계산하면 굉징히 작은 양의 상수 h(예를 들어, 0.0001)에 대해 f'(2) ≒ (f(2+h) - f(2-h))/(2*h) = (f(2.0001) - f(1.9999)) / 0.0002 = 4와 같이 미분을 하지 않고도 함수값만을 이용하여 근사할 수 있습니다. 또한 이차미분의 경우도 유사한 방식으로 근사적 계산이 가능합니다. 이와 같이 Newton 방법에서 Hessian의 계산을 근처 함수값을 이용하여 근사적으로 numeric하게 계산하여 사용하는 최적화 기법들을 Quasi-Newton (쿼지-뉴턴) 방법이라고 부릅니다. Hessian을 구체적으로 어떻게 근사하느냐에 따라서 여러 Quasi-Newton 방법들이 있으며 그중 가장 대표적으로 사용되는 방법이 BFGS(Broyden–Fletcher–Goldfarb–Shanno) 방법입니다. 구체적인 수식 등 보다 자세한 내용에 대해서는 위키피디아 등을 참고하시기 바랍니다.
11. 맺음말
근 3주에 걸쳐 짬짬히 썼던 글을 이제 슬슬 마무리할 때가 된 것 같습니다. 보통 최적화 관련 이론서나 위키피디아 설명 등을 보면 그 엄청난 수식과 이론들에 먼저 눈앞이 깜깜해짐을 느낍니다. 저도 그랬고 대부분 그럴 것이라고 생각합니다. 하지만 그 복잡한 수식들을 걷어내고 나면 그 이면에는 이들이 매우 단순한 원리에 의해 움직이고 있음을 알수 있습니다. 부족하나마 이 글이 현상의 이면을 볼 수 있는 작은 실마리가 될 수 있길 기대합니다.
by 다크 프로그래머